Guide¶


Intro¶
ProSiT - PROgressive SImilarity Thresholds is an algorithm for topic models. Given a corpus of texts, it will find latent dimensions corresponding to the main topics present in the corpus, providing for each of them the relative keywords (descriptors).
It is input agnostic: it can deal with any kind of textual representations, be they vectors resulting from, for example, Bag of Words - BoW or State Of The Art - SOTA (multi-lingual) Language Models - LMs.
ProSiT is deterministic and fully interpretable.
It does not require any assumption regarding the possible number of topics in a corpus of documents: they are automatically identified given two tunable similarity parameters, \(\alpha\) and \(\beta\).
The \(\alpha\) parameter is used to determine the minimum Cosine Similarity Threshold - CST to consider different documents as related to the same latent dimension, i.e. topic. PRoSiT is an iterative algorithm, that finds these latent dimensions in different epochs, where the overall number of data points is progressively reduced, as step by step each set of points lying within the given threshold is collapsed into its centroid. In this procedure, growing cosine similarity thresholds are needed to prevent all the data points from falling into their global centroid. Therefore, the \(\alpha\) parameter is used in the following formula, that provides higher CSTs at every epoch:
This produce this kind of curves,:
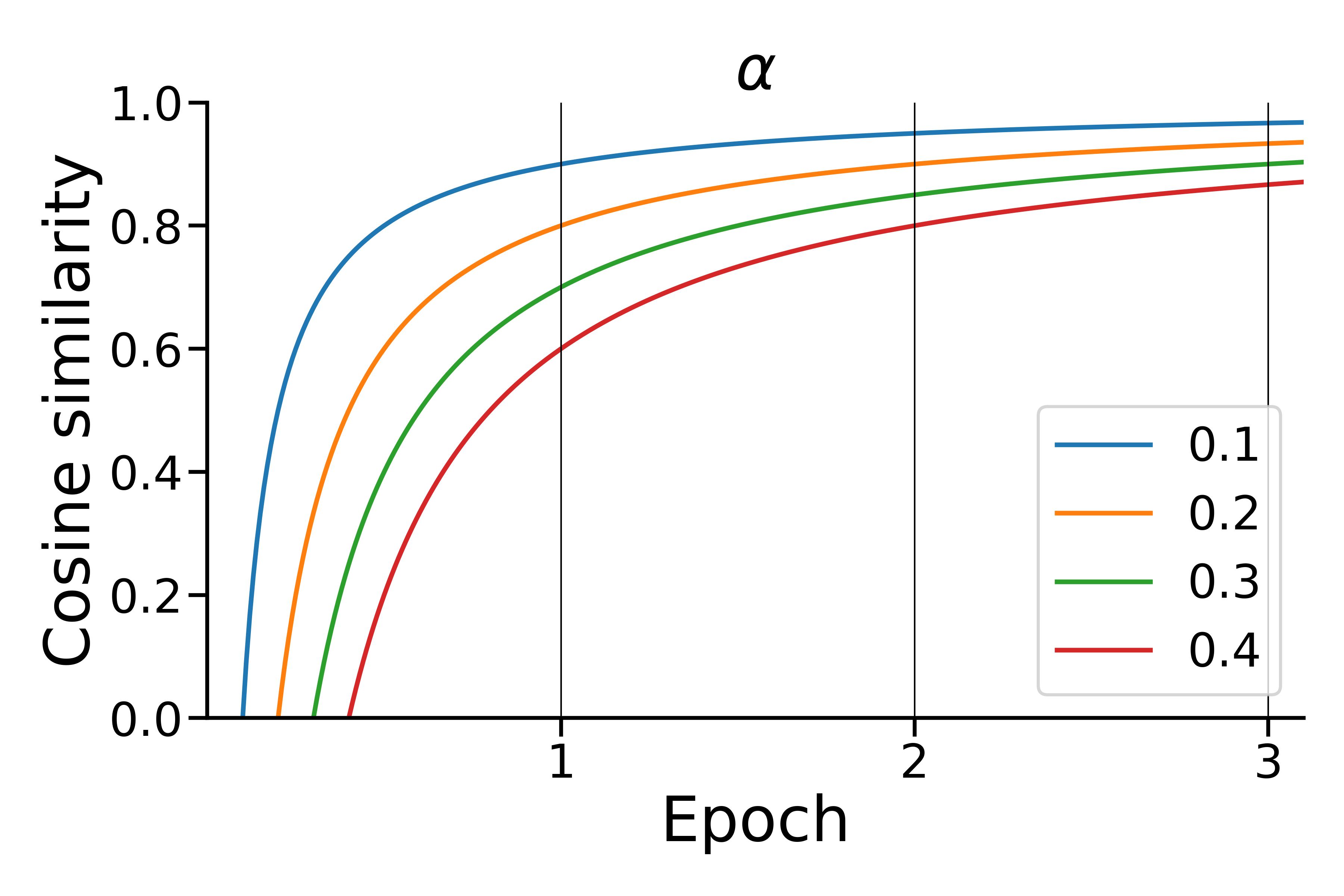
Epoch by epoch, reducing the number of data points into smaller sets of latent dimensions, ProSiT produces several hypotheses of groups of topics/latent dimensions. To extract from them their main keywords, for each latent dimension we need to determine which documents we want to consider. To this aim we use the parameter \(\beta\), which represent the percentage of the documents, the most close to the latent dimension, that will be considered. For example, \(\beta = .1\) means that, considering the closest documents to the topic, the top 10% will be taken into consideration. In practice, \(\beta\) affects the level of specificity that will be considered as satisfying, for each set of descriptors.